오늘은 크롤링 하는법을 퀴즈를 통해 다시 한번 숙지하는 날
그리고 마지막엔 역시 대망의 숙제 ㅠ_ㅠ ㅋㅋ
숙제는 참 어렵다 ㅎ
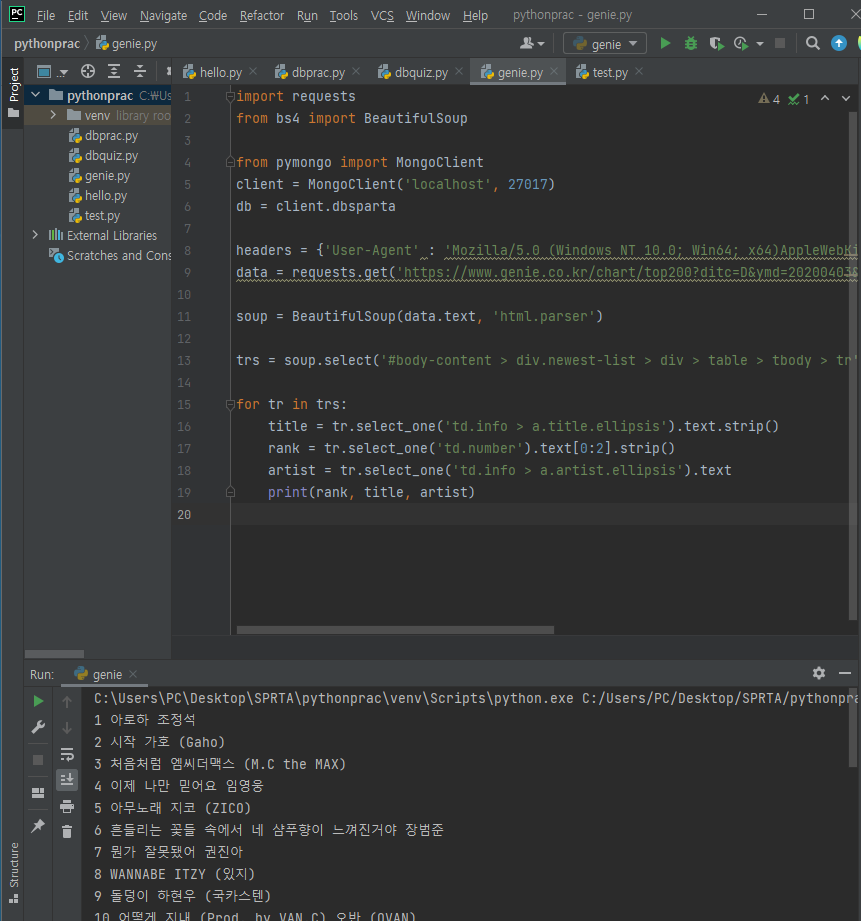
오늘의 포인트는 크롬의 개발도구로 그 싸이트의 정보를 퍼오는 방법임
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
를 먼저 붙여 주고 src 란에다 크롤링 할 주소를 붙여넣는다.
그리고
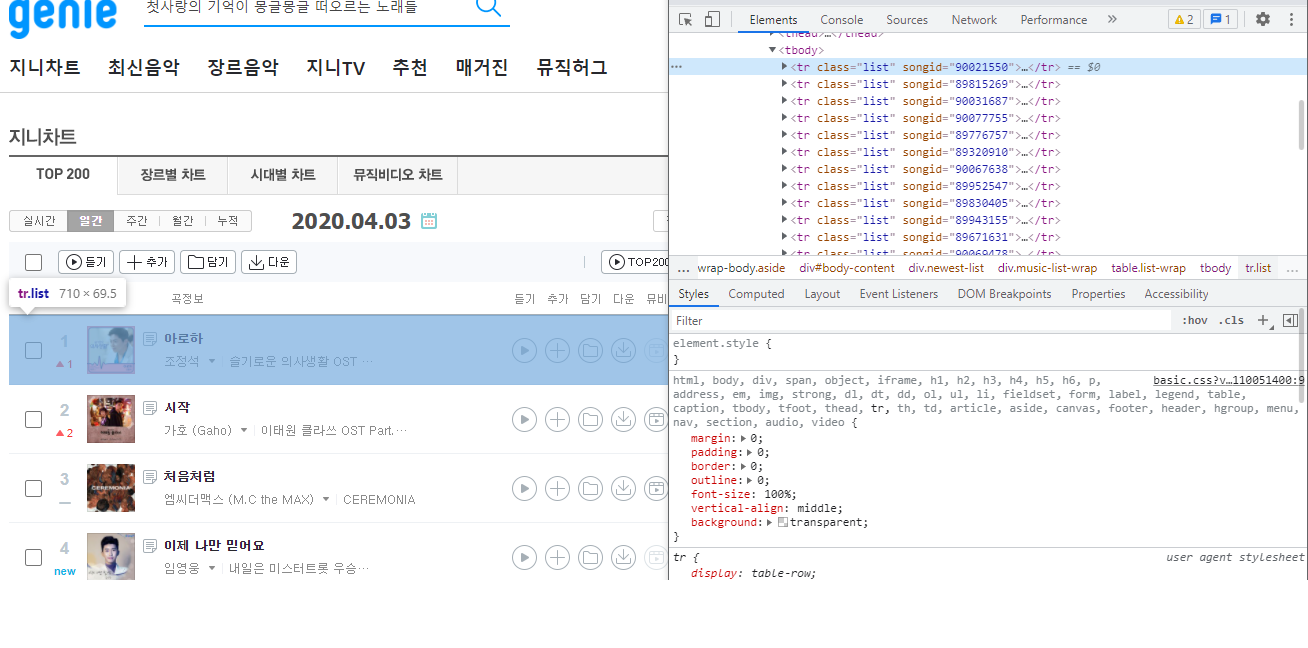
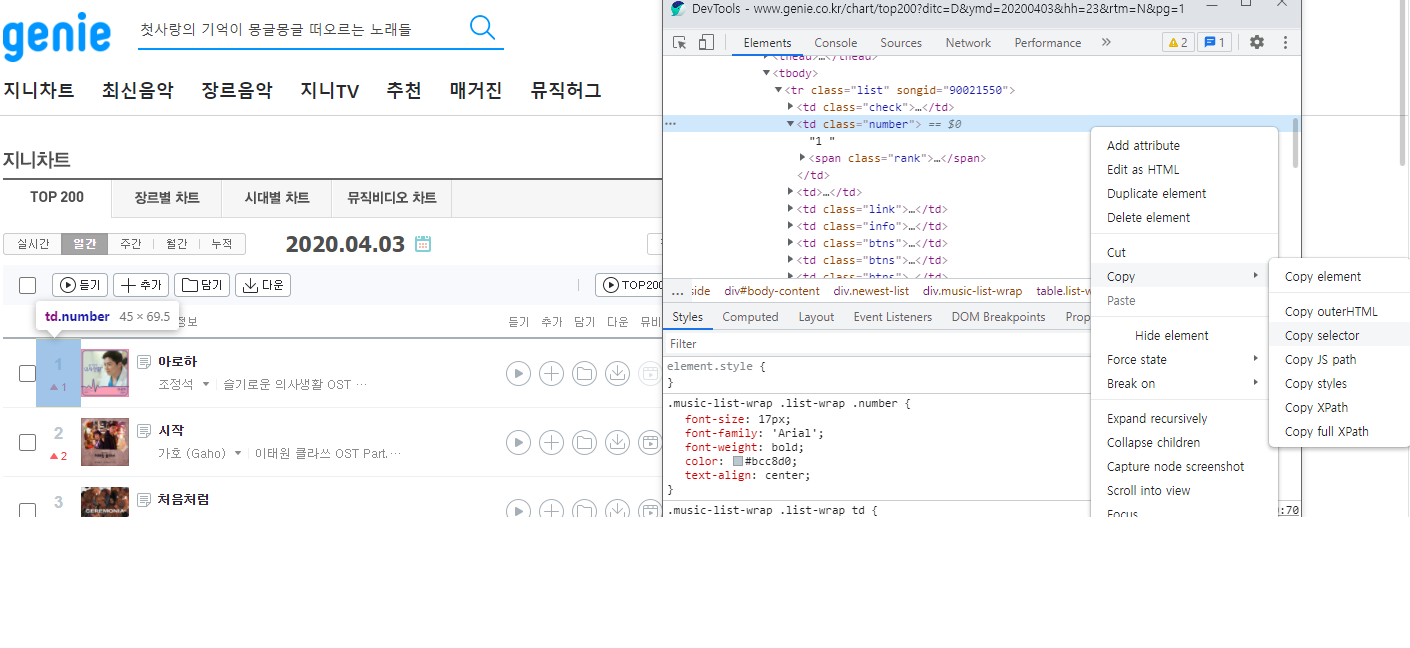
크롤링 할 부분을 선택해서 원하는 부분을 선택
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
#body-content > div.newest-list > div > table > tbody > tr:nth-child(2) > td.number
'아로하'와 '시작' 을 눌러서 필요한것을 퍼오면 공통된 부분이 보이는데 이게 바로 시작 경로임
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
soup.selcet('경로') - 명령어로 경로를 설정해주고 trs = 위 경로에서 가져온 값이라는 것을 설정 해줌
for tr in trs: - trs에서 설정된 경로에서 tr을 출력해보자
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
title 타이틀은 = tr.은 한개선택된(경로)인데
이 경로를 찾는 것은
아까 위에 경로에서처럼 필요한 값들이 있다.
예를 들면 타이틀이라면

#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
라는 경로가 나왔으면
주 경로 제외 하고 변화되는 부분을 제외 하고 값을 정하는 또다른 경로를 입력
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
title 타이틀은 = tr. 은 한개선택된(경로를) .글로 만들어라 .text .strip() <- (이건 공백을 없에는 명령어)
rank = tr.select_one('td.number').text[0:2].strip()
아 저기의 text[0:2] 는 0 부터 2 번째 글자열까지 잘라서 표시 해주는 명령어
실제 지니 page는 1~50위 까지 순위만 나오기때문에 필요한것은 2글자
(안넣어주면 상승, 하강 같은 랭크 밑에 아이콘같은 명칭들이 따라 옴)
그래서 잘라주어야 함
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)
이런 방식으로 title, rank, artist를 전부 지정해주면
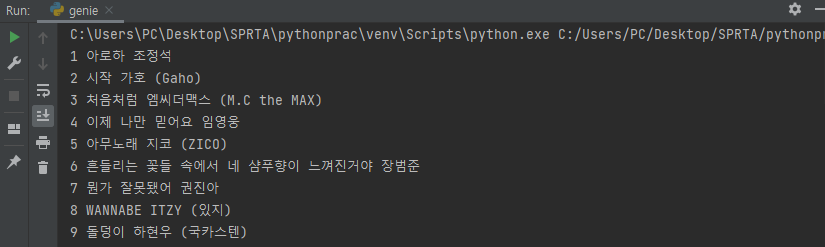
이런식으로 출력되게 된다.
어휴..... 어렵다.
'개발 교육' 카테고리의 다른 글
| 스파르타 코딩 메이킹챌린지 개발일지-1 (0) | 2021.12.14 |
|---|---|
| [왕초보]비개발자를 위한 웹개발 종합반(프로그래밍실무, 풀스택) (0) | 2021.11.04 |
| 스파르타 코딩 웹개발 6일차 (0) | 2021.10.30 |
| 스파르타 코딩 웹개발 5일차 (0) | 2021.10.29 |
| 스파르타 코딩 웹개발 4일차 (0) | 2021.10.28 |



